Shivanker kumar for the class of May 9th
z-score and its application

z-score and its application
Z-scores are
expressed in terms of standard deviations from their means. Resultantly, these
z-scores have a distribution with a mean of 0 and a standard deviation of 1.
The formula for calculating the standard score is given below:
Standard
Score Calculation
Z = (X-µ)/s
Z = (X-µ)/s
As the
formula shows, the standard score is simply the score, minus the mean score,
divided by the standard deviation. Let’s see the application of z-score.
Application –
1. How well did Sarah perform in her
English Literature coursework compared to the other 50 students?
To answer
this question, we can re-phrase it as: What percentage (or number) of students
scored higher than Sarah and what percentage (or number) of students scored
lower than Sarah? First, let's reiterate that Sarah scored 70 out of 100, the
mean score was 60, and the standard deviation was 15 (see below).
Score Mean Standard
Deviation
(X) µ s
70 60 15
In terms of
z-scores, this gives us:
Z = (X-µ)/s = (70-60)/15 = .6667
Standard
Score Calculation
The z-score
is 0.67 (to 2 decimal places), but now we need to work out the percentage (or
number) of students that scored higher and lower than Sarah. To do this, we
need to refer to the standard normal distribution table.
This table
helps us to identify the probability that a score is greater or less than our
z-score score. To use the table, which is easier than it might look at first
sight, we start with our z-score, 0.67 (if our z-score had more than two
decimal places, for example, ours was 0.6667, we would round it up or down
accordingly; hence, 0.6667 would become 0.67). The y-axis in the table highlights
the first two digits of our z-score and the x-axis the second decimal place.
Therefore, we start with the y-axis, finding 0.6, and then move along the
x-axis until we find 0.07, before finally reading off the appropriate number;
in this case, 0.2514. This means that the probability of a score being greater
than 0.67 is 0.2514. If we look at this as a percentage, we simply times the
score by 100; hence 0.2514 x 100 = 25.14%. In other words, around 25% of the
class got a better mark than Sarah (roughly 13 students since there is no such
thing as part of a student!).
Going back
to our question, "How well did Sarah perform in her English Literature
coursework compared to the other 50 students?", clearly we can see that
Sarah did better than a large proportion of students, with 74.86% of the class
scoring lower than her (100% - 25.14% = 74.86%). We can also see how well she
performed relative to the mean score by subtracting her score from the mean
(0.5 - 0.2514 = 0.2486). Hence, 24.86% of the scores (0.2486 x 100 = 24.86%)
were lower than Sarah's, but above the mean score. However, the key finding is
that Sarah's score was not one of the best marks. It wasn't even in the top 10%
of scores in the class, even though at first sight we may have expected it to
be. This leads us onto the second question.
2. Which students came in the top 10%
of the class?
A better way
of phrasing this would be to ask: What mark would a student have to achieve to
be in the top 10% of the class and qualify for the advanced English Literature
class?
To answer
this question, we need to find the mark (which we call "X") on our
frequency distribution that reflects the top 10% of marks. Since the mean score
was 60 out of 100, we immediately know that the mark will be greater than 60.
After all, if we refer to our frequency distribution below, we are interested
in the area to the right of the mean score of 60 that reflects the top 10% of
marks (shaded in red). As a decimal, the top 10% of marks would be those marks
above 0.9 (i.e., 100% - 90% = 10% or 1 - 0.9 = 0.1).

First, we
should convert our frequency distribution into a standard normal distribution.
As such, our mean score of 60 becomes 0 and the score (X) we are looking for,
0.9, becomes our z-score, which is currently unknown.
The next
step involves finding out the value for our z-score. To do this, we refer back
to the standard normal distribution table.


In answering
the first question in this guide, we already knew the z-score, 0.67, which we
used to find the appropriate percentage (or number) of students that scored
higher than Sarah, 0.2514 (i.e., 25.14% or roughly 25 students achieve a higher
mark than Sarah). Using the z-score, 0.67, and the y-axis and x-axis of the
standard normal distribution table, this guided us to the appropriate value,
0.2514. In this case, we need to do the exact reverse to find our z-score.
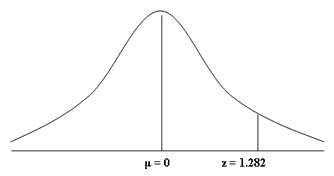
We
know the percentage we are trying to find, the top 10% of students, corresponds
to 0.9. As such, we first need to find the value 0.9 in standard normal
distribution table. When looking at the table, you may notice that the closest
value to 0.9 is 0.8997. If we take the 0.8997 value as our starting point and
then follow this row across to the left, we are presented with the first part
of the z-score. You will notice that the value on the y-axis for 0.8997 is 1.2.
We now need to do the same for the x-axis, using the 0.8997 value as our
starting point and following the column up. This time, the value on the x-axis
for 0.8997 is 0.08. This forms the second part of the z-score. Putting these
two values together, the z-score for 0.8997 is 1.28 (i.e., 1.2 + 0.08 = 1.28).
There
is only one problem with this z-score; that is, it is based on a value of
0.8997 rather than the 0.9 value we are interested in. This is one of the
difficulties of refer to the standard normal distribution table because it
cannot give every possible z-score value (that we require a quite enormous
table!). Therefore, you can either take the closest two values, 0.8997 and
0.9015, to your desired value, 0.9, which reflect the z-scores of 1.28 and
1.29, and then calculate the exact value of "z" for 0.9, or you can
use a z-score calculator. If we use a z-score calculator, our value of 0.9
corresponds with a z-score of 1.282. In other words, P ( z > 1.282 ) = 0.1.


{kind=link}
Now
that we have the key information (that is, the mean score, µ, the standard
deviation, s , and z-score, z), we can answer our question directly, namely:
What mark would a student have to achieve to be in the top 10% of the class and
qualify for the advanced English Literature class? First, let us reiterate the
facts:
Score
|
Mean
|
Standard Deviation
|
z-score
|
(X)
|
µ
|
s
|
z
|
?
|
60
|
15
|
1.282
|
To
find out the relevant score, we apply the following formula:

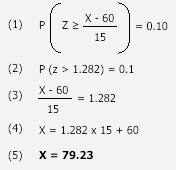{kind=link}
Therefore,
students that scored above 79.23 marks out of 100 came in the top 10% of the
English Literature class, qualifying for the advanced English Literature class
as a result.
Hope you find it important and relevant!!
its useful application related post!!!
ReplyDeleteGranular Analytics
Analytics for Micro Markets
Hyper-Local Data
Hyper Local insights
z-score and its application useful blog!!!
ReplyDeleteDealer Clusters in Gurugram
Market Index in Mumbai
Sales Opportunities in Mumbai
Category sales in Mumbai